个人本地部署deepseek-r1指南
前言¶
在AI技术快速发展的今天,部署和展示AI模型是一个非常重要的技能。本文将指导你如何在本地部署DeepSeek-R1,并通过客户端工具或网页界面进行展示
如果你电脑配置不错,且期望不受网络限制也可以流畅使用deepseek,那就开始吧~~
安装ollama¶
Ollama是一个开源的 LLM(大型语言模型)服务工具(就是大模型运行工具),用于简化在本地运行大语言模型,降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型。

ubuntu-cpu¶
官方GitHub地址: GitHub - ollama/ollama
我们这里采用docker的方式来安装
https://hub.docker.com/r/ollama/ollama
我们这里只考虑仅仅是cpu的情况,英伟达gpu可以参考上面链接里面的安装指南
window-amd显卡¶
因为默认官方ollama提供amd的支持到RX6800显卡,低版本不支持,查看链接
System requirements (Windows) — HIP SDK installation (Windows)
对于官方支持 HIP SDK 的显卡,只需要下载并安装 AMD 官方版本的 ROCm 和 Ollama 的官方版本就能直接使用。
所以有了开源大神做了一个amd分支,本文主要是介绍对于官方不支持的显卡应该如何安装并使用 ROCm 和 ollama。
ollama-for-amd开源地址¶
Releases · likelovewant/ollama-for-amd · GitHub
下载 ROCmLibs¶
下载对应显卡型号的压缩包,由于我的显卡是6750gre,LLVM target是gfx1031
Release v0.6.1.2 · likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU · GitHub
那么我这里就需要下载 rocm.gfx1031.for.hip.sdk.6.1.2.7z
下载安装ollama-for-amd¶
下载完成后运行安装包一键安装完成,安装成功后运行 ollama,对于官方不支持的版本,也可以进行编译,编译请参考地址:Home · likelovewant/ollama-for-amd Wiki · GitHub
我这里采用下面这个安装包直接安装
修改 ollama-for-amd¶
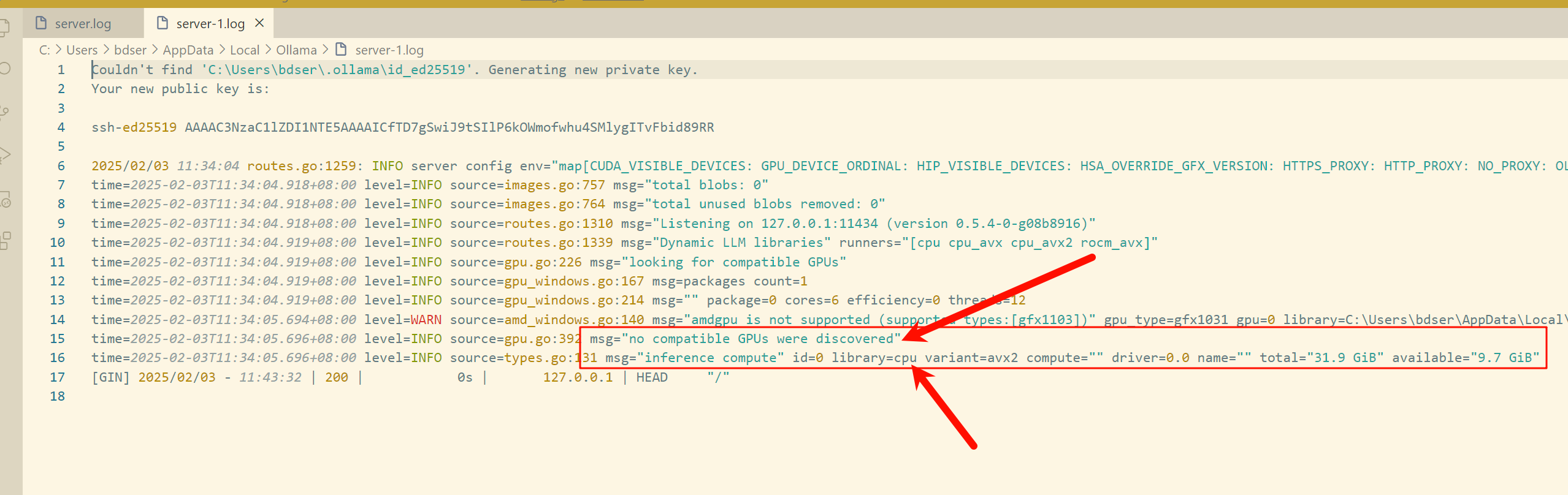
从log中我们可以看到 ollama 没有跑在显卡上,输出没有发现兼容的显卡,直接查看server.log里面的内容
server.log
现在需要用之前下载 的ROCmLibs
打开软件安装目录,比如这是我的安装路径 C:\Users\lin\AppData\Local\Programs\Ollama\lib\ollama
- 将压缩包中的
rocblas.dll替换C:\Users\lin\AppData\Local\Programs\Ollama\lib\ollama\rocblas.dll - 将压缩包中的
library文件夹替换C:\Users\lin\AppData\Local\Programs\Ollama\lib\ollama\rocblas\library
退出 ollama 并重新运行

安装deepseek-r1¶
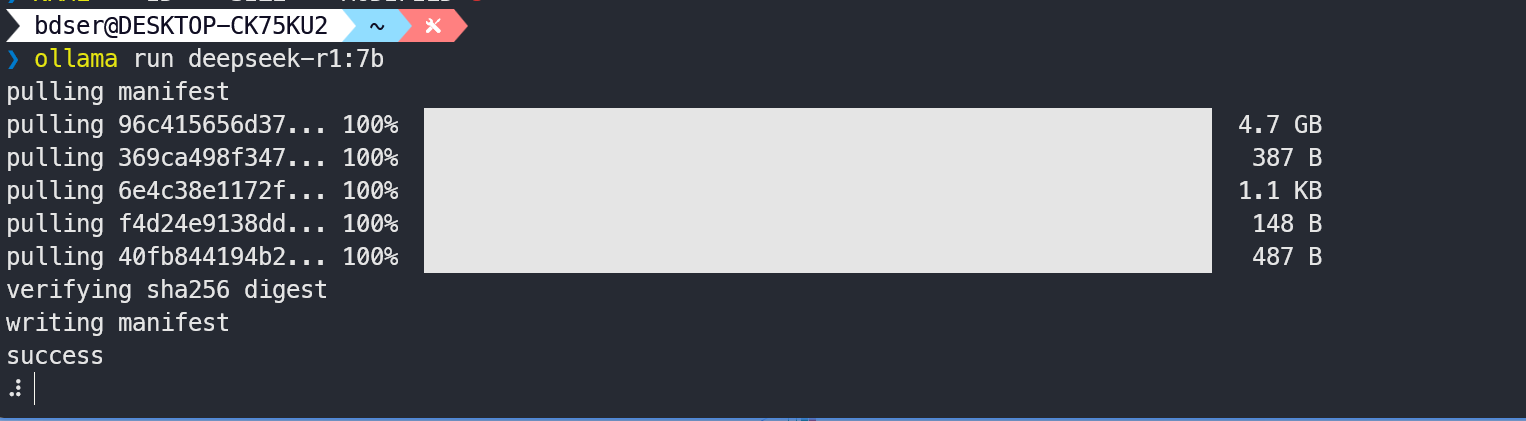
安装完成以后,我们可以启动ollama,接下来可以通过终端进行对话
ubuntu-cpu

windows-amd显卡
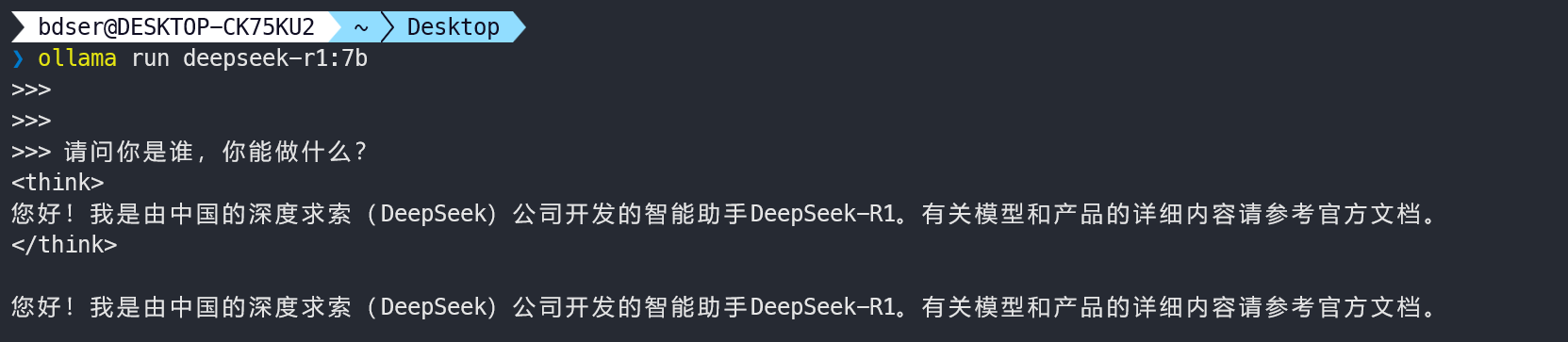
window-amdGPU显卡使用效果¶
可以说效果非常明显,GPU回答的流式速度很快,比上面ubuntu-cpu环境快很多,利用率最高峰值的时候接近100%,充分利用,等答复完毕后,立马降下来,果然还是有GPU很香

windows客户端安装¶
地址:Chatbox AI官网
我们使用本地模型,然后输入


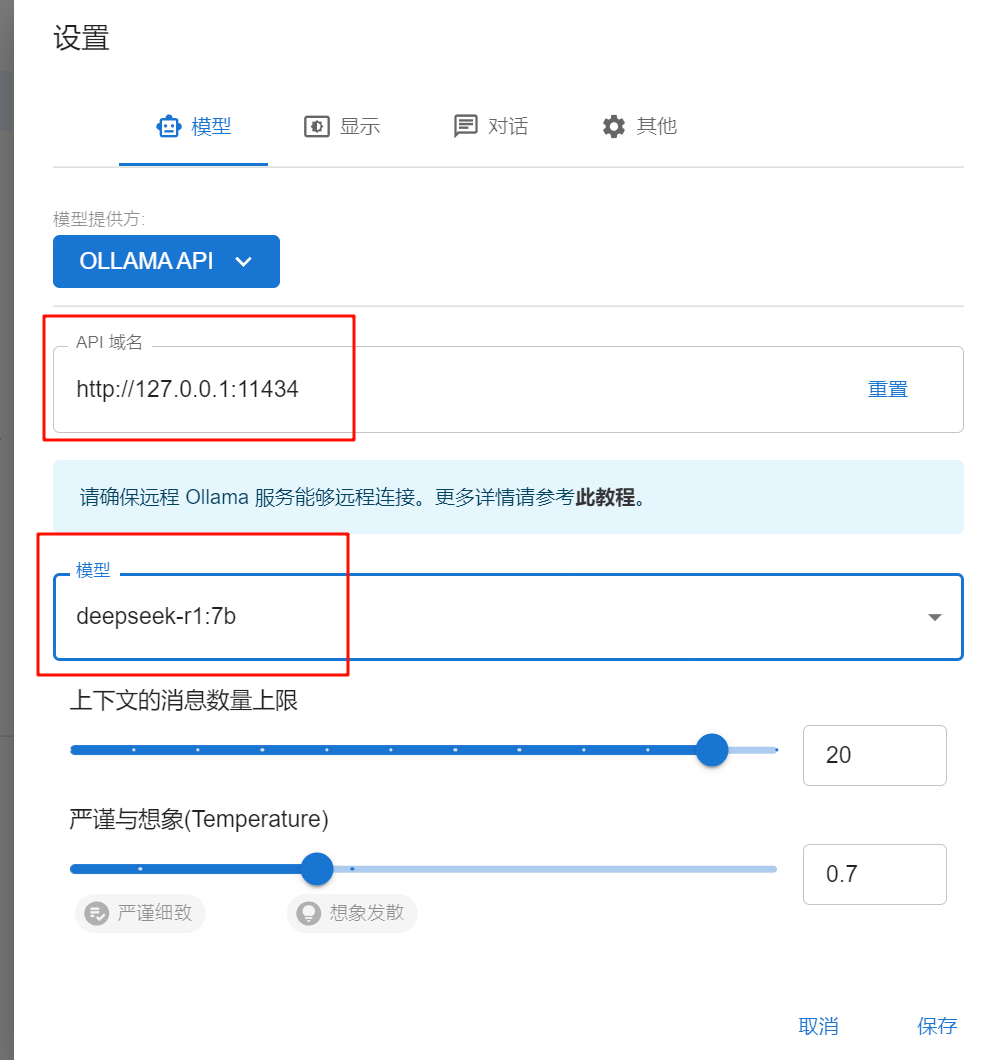

网页版客户端安装¶
可以参考上一篇公众号的open-webgui配置,可以通过open-webgui来进行对话

补充下配置open-webgui ,右上角用户logo处,右键管理员配置 ,然后如下图,根据自己的地址和端口进行配置,最后有个旋转箭头是测试验证,可以自己验证下

总结¶
我们通过ollama 大模型工具来安装deepseek-r1,解决了ollama对低版本amd显卡的支持
有三种对话聊天方式,第一种是终端,第二种是Chatbox,第三种是open-webgui方式都可以进行交流 ,好了,可以搭建起来进行玩玩了祝你成功
博客链接 (想看无码大图请访问博客地址) https://wiki.budongshu.cn/ (酷酷分享栏目下面)